
En este capítulo se expondrán las técnicas necesarias para el desarrollo y la creación de un gráfico de cajas en R.
Este tipo de gráficos estadísticos no es más que una representación gráfica de un conjunto de datos que brinda una impresión visual de la localización, dispersión, grado y dirección del sesgo.
En el caso de una distribución que se aproxima a la forma de campana (de Gauss, es decir, a la curva normal), el gráfico de caja también, permite identificar los valores atípicos.
Para el diseño de estas gráficas, disponemos, en R, la función boxplot(), y para su demostración, usaremos un ejemplo de aplicación.
Dicho ejemplo, consta de un estudio realizado sobre los picos de electricidad, en kV, que soporta los televisores:
| Picos de Tensión en Televisores, kV | |||
| 2.0 | 5.0 | 4.5 | 5.4 |
| 4.2 | 4.3 | 5.1 | 5.6 |
| 5.2 | 4.7 | 4.4 | 5.8 |
| 5.2 | 7.8 | 5.4 | 4.9 |
| 4.6 | 4.6 | 5.0 | 4.8 |
| 5.3 | 5.2 | 5.3 | 5.9 |
Introducimos los elementos en la variable dato mediante la función scan():
> datos <- scan()
1: 2.0 5.0 4.5 5.4
5: 4.2 4.3 5.1 5.6
9: 5.2 4.7 4.4 5.8
13: 5.2 7.8 5.4 4.9
17: 4.6 4.6 5.0 4.8
21: 5.3 5.2 5.3 5.9
25:
Read 24 items
Y aplicamos la función boxplot() tal cual:
> boxplot(datos)
Obteniendo el siguiente gráfico:
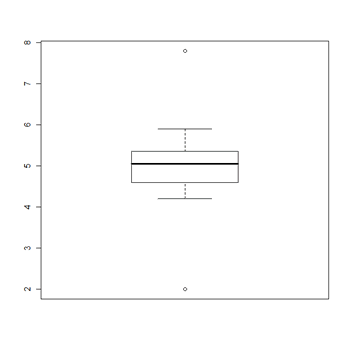
- x: Los datos que van a ser representados mediante boxplot. Puede ser un conjunto de vectores separados, cada uno correspondiendo a un gráfico de caja diferente, componente o una lista que contiene a tales vectores. Alternativamente, una especificación de la forma “x » g” puede ser dada para indicar que las observaciones en el vector ”x” van a ser agrupadas de acuerdo a los niveles del factor “g”. En este caso, el argumento “data” puede usarse para par valores para la variables en la especificación. "NA" son permitidos en los datos.
- range: Determina la extensión de la parcela de la caja. Si es positivo, la parcela se extienden hasta el dato más extremo, el cual no es más que el “rango”, por rango intercuartílico de la caja. Un valor de cero hace que la parcela se extiendan hasta los datos extremos.
- width: Un vector que da los anchos relativos de las cajas.
- varwidth: Si es “TRUE”, las cajas son dibujadas con anchos proporcionales a las raíces cuadradas del número de observaciones en los grupos.
- notch: Si es “TRUE”, una cuña es dibujada a cada lado de las cajas. Cuando las cuñas de dos gráficos de caja no se traslapan, entonces las medianas son significativamente diferentes a un nivel del 5%.
- outline: Si es "FALSE", los puntos atípicos no se representan en el gráfico (como los puntos S+ que utiliza líneas). Por defecto, su valor es de "TRUE".
- names: Un grupo de etiquetas a ser impresas debajo de cada gráfico de cajas.
- boxwex: Un factor de escala a ser aplicado a todas las cajas. Cuando sólo hay unos pocos grupos, la apariencia del gráfico puede mejorarse haciendo las cajas más angostas.
- data: “data.frame”, “list”, o “environment” en el cual los nombres de las variables son evaluados cuando “x” es una fórmula.
- plot: Si es “TRUE” (por defecto) entonces se produce el gráfico. De lo contrario, se producen los resúmenes del gráfico de cajas.
- border: Un vector opcional de colores para las líneas de las cajas y debe ser de longitud igual al número de gráficos.
- col: Si se especifica, los colores que contienen serán usados en el cuerpo de las cajas.
- log: Para indicar si las coordenadas “xy”, serán representadas en escala logarítmica.
- pars: Los parámetros gráficos pueden ser pasados como argumentos para el boxplot.
- horizontal: Si es “FALSE” (por defecto) las gráficas de cajas son dibujados verticalmente.
- add: Si es “TRUE” agrega un gráfico de caja al gráfico actual.
- formula: Una fórmula tal como “y » x”.
- data: Un data.frame (o lista) del cual, las variables en “fórmula” serán tomadas.
- subset: Un vector opcional para especificar un subconjunto de observaciones a ser usadas en el proceso de ajuste.
- na.action: Una función la cual indica lo que debería pasar cuando los datos contienen “NA”.
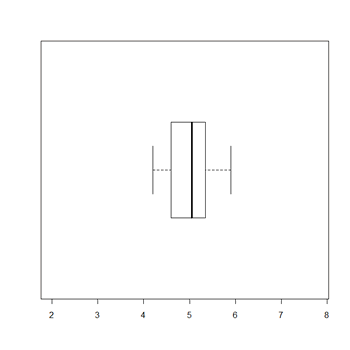
Por ejemplo, si queremos el gráfico de cajas en horizontal y sin que se representen los datos atípicos:
> boxplot(datos, horizontal=T, outline=F)
Obtenemos:
> boxplot(datos, plot=F)
$stats
.....[,1]
[1,] 4.20
[2,] 4.60
[3,] 5.05
[4,] 5.35
[5,] 5.90
$n
[1] 24
$conf
........[,1]
[1,] 4.808113
[2,] 5.291887
$out
[1] 2.0 7.8
$group
[1] 1 1
$names
[1] "1"
Los objetos que nos ofrece son:
- stats: Una matriz, cada columna contiene el extremo inferior de la parcela, el cuartil 1, la mediana, el cuartil 3 y el extremo de la parte superior de la parcela.
- n: Un vector con el número de observaciones en cada grupo.
- conf: Una matriz donde cada columna contiene los extremos inferior y superior de la muesca.
- out: Los valores de los datos de puntos atípicos.
- group: Un vector de la misma longitud que out, cuyos elementos indican a qué grupo pertenece el outlier.
- names: Un vector de nombres para los grupos.
Esta forma de obtener información, es de gran utilidad ya que podemos asignársela a una variable para posteriormente, poder acceder de forma individual a cada sección:
> televisores <- boxplot(datos, plot=F)
> televisores$out
[1] 2.0 7.8
R, también dispone de hacer este tipos de gráficos mediante elementos estadísticos, para ello, está la función boxplot.stat(), actúa de forma similar pero los argumentos son los elementos estadísticos básicos necesarios para poder representar este tipo de gráficos.
Por supuesto, se recomienda que se use la ayuda integrada en R para ampliar conocimientos sobre las funciones o objetos en este capítulo expuestos:
> ?"boxplot"
En resumen, los gráficos de cajas, son de utilidad cuando se pretende comparar dos o más conjuntos de datos.




0 comentarios:
Publicar un comentario