
En este capítulo se abordará las expresiones matemáticas básicas para la Estimación y Pruebas de Hipótesis.
Normalmente, se suele denominar: Inferencia Estadística, que no es más que, los métodos utilizados para tomar decisiones o para sacar conclusiones sobre una población. Para ello, se utilizan la información contenida en una muestra de la población.
Estimación Puntual.
Sea θ, un parámetro desconocido de la población de interés, y sea X1, X2, ..., Xn una muestra aleatoria de tamaño n de dicha población. Se llama estimador puntual θ, al estadístico  que se usa para estimar el valor del parámetro θ.
que se usa para estimar el valor del parámetro θ.
Por lo tanto, un estimador puntual del parámetro θ de una población, es un valor numérico  del estimador puntual
del estimador puntual  .
.
· Estimador Insesgado para el parámetro θ:  .
.
· Sesgo del estimador  :
:  .
.
· Error Cuadrático Medio: 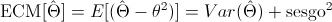 .
.
Sean  y
y  dos estimadores puntuales para el parámetro θ. Se define la eficiencia relativa de
dos estimadores puntuales para el parámetro θ. Se define la eficiencia relativa de  con respecto a
con respecto a  como el cociente:
como el cociente:

Si dicha cantidad es menor que 1, entonces decimos que
 es más eficiente que
es más eficiente que  .
.· Estimador de Máxima Verosimilitud de θ: Sea X una variable aleatoria con función de probabilidad (o densidad de probabilidad) f(x, θ), donde θ es un parámetro desconocido. Sean x1, x2, ..., xn los valores observados de una muestra aleatoria de tamaño n de X.
La función de verosimilitud de la muestra es:
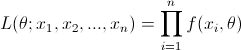
El estimador de máxima verosimilitud de θ, es el valor de θ que maximiza la función de verosimilitud.
Teoría Central del Límite.
Sea X1, X2, ..., Xn una muestra aleatoria de tamaño n de una distribución con media μ y varianza σ2. Entonces, el límite de la distribución de:
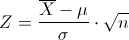
Cuando n -> ∞, es la distribución normal estándar.
Sean X1 y X2 dos poblaciones normales independientes con medias μ1 y μ2, y varianzas σ21 y σ22. Si
 y
y  son las medias muestrales de dos muestras aleatorias independientes de tamaños n1 y n2 de estas poblaciones, entonces:
son las medias muestrales de dos muestras aleatorias independientes de tamaños n1 y n2 de estas poblaciones, entonces: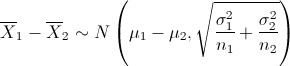
Si en las condiciones de la Teoría Central del Límite, las variables X1 y X2 no siguen distribuciones normales, entonces, el límite de la distribución es:
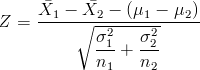
Cuando n1 y n2 -> ∞, es la distribución normal estándar.
Error Estándar.
El error estándar de un estadístico es la desviación típica de su distribución muestral. Si el error estándar involucra parámetros desconocidos de la población, cuyos valores pueden estimarse, entonces la sustitución de los parámetros por estas estimaciones en el error estándar, da como resultado el error estándar.
Por ejemplo: X ~ N(μ, σ), el error estándar de
 es
es  .
.Y el error estándar estimado de
 es
es  .
.Distribución Ji-Cuadrada.
Sean Z1, ..., Zk variable aleatorias normales independientes, con media μ = 0, y varianzas σ2 = 1. Entonces, la variable aleatoria:
Tiene una función de densidad de probabilidad:
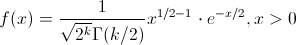
Y se dice que sigue una distribución ji-cuadrada con k grados de libertad. Se representa por X ~ X2k.
· Esperanza: E(X) = k
· Varianza: V(X) = 2k.
· Puntos Críticos: X2α, k es tal que: P(X > X2α, k) = α.
Distribución t-Student.
Sean las variables aleatorias Z ~ N(0, 1) y V ~ X2k. Si Z y V son independientes, entonces, la variable aleatoria es:
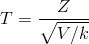
Tiene una función de densidad de probabilidad:
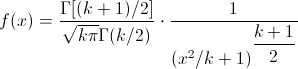
Para -∞ < . x < . ∞. Y se dice que sigue una distribución t-Student con k grados de libertad. Se representa por T ~ tk.
Dicha función posee una curva simétrica y sus colas son más amplias que las de la distribución normal.
· Esperanza: E(X) = 0, para k > 2.
· Varianza: V(X) = k/(k-2), para k > 2.
· Puntos Críticos: tα, k es tal que: P(T > tα, k) = α.
Distribución F de Snedecor.
Sean X1 y X2 variables aleatorias ji-cuadradas independientes con grados de libertad k1 y k2 respectivamente. Entonces, la variable aleatoria es:
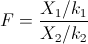
Tiene una función de densidad de probabilidad:
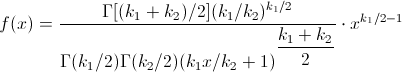
Para x > 0. Y se dice que sigue una distribución F de Snedecor con k1 grados de libertad en el numerador y k2 grados de libertad en el denominador. Se representa por F ~ Fk1,k2.
· Esperanza:
 , para k2 > 2.
, para k2 > 2.· Varianza:
 , para k2 > 4.
, para k2 > 4.· Puntos Críticos: fα, k1, k2 es tal que: P(F > fα, k1, k2) = α.
Hay que tener en cuenta que:
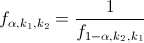 .
.Estimación Por Intervalos.
Una estimación por intervalos de un parámetro desconocido θ, es un intervalo de la forma [l, u], donde los extremos l y u, dependen de la estimación puntual
 para una muestra particular, y de la distribución muestral de
para una muestra particular, y de la distribución muestral de  .
.Los extremos l y u son valores de las variables aleatorias L y U respectivamente y reciben el nombre de límites de confianza inferior y superior.
Una prueba de hipótesis estadística es un procedimiento que conduce a una decisión sobre una hipótesis. Esta decisión se toma a partir de una muestra aleatoria de la población de interés.
Si la información contenida en la muestra es consistente con la hipótesis, se concluye que ésta es verdadera. En otro caso, se concluye que ésta es falsa.
· H0 es la hipótesis que se desea probar.
· H0 se plantea siempre de modo que especifique un valor exacto del parámetro.
· La prueba de hipótesis involucra la toma de una muestra aleatoria, el cálculo de un estadístico a partir de la muestra aleatoria, y el uso del mismo para tomar una decisión sobre H0.
· Error Tipo I: Rechazo de H0 cuando H0 es verdadera.
· Nivel de significación α: Probabilidad de error del Tipo I.
· Nivel de significación β: Probabilidad de error del Tipo II.
| Decisión | H0 es Verdadera | H0 es Falsa |
| Aceptar Ho | No hay Error | Error del Tipo II |
| Rechazar Ho | Error del tipo I | No hay Error |
· p-Valor: Es el nivel de significación más pequeño que conduce al rechazo de H0.
 | Estimación, Intervalos de Confianza y Pruebas de Hipótesis | |
 | Estimación, Intervalos de Confianza y Pruebas de Hipótesis |
| Problemas: Estimador de Máxima Verosimilitud. | |
| Problema 1 | Problema 6 |
| Problema 2 | Problema 7 |
| Problema 3 | Problema 8 |
| Problema 4 | Problema 9 |
| Problema 5 | Problema 10 |




36 comentarios:
Muy buena pagina! me fue de gran ayuda para elavorar mi formulario de un examen de estadistica
Buenas:
Me alegro muchísimo de que te haya sido de utilidad el contenido que este blog, Aqueronte, ofrece.
Gracias por los ejercicios resueltos me fueron de gran ayuda
Hola Manuel,
Primeramente felicitarte por tu blog, me está siendo de mucha ayuda.
Las imagenes no se ven bién.
Un saludo
Buenas,
Tengo unas dudas:
Me parece que anteriormente la parte de Contraste de hipótesis estaba más detallado.
La primera es:
- Cuando utilizo alpha, cuando alpha/2, y cuando 1-alpha/2 ???
- Cuando es unilateral acepto si el valor de la media (Muestral o poblacional) es menor/Mayor a la obtenida??
- Cuando es bilateral acepto si el valor de la media (Muestral o poblacional) pertenece a intervalo obtenido??
Grácias
-
Buenas:
No es que estuviera más detallado, sólo que estaba ciertos intervalos de confianza expuestos. Los he quitado ya que están en la tabla todos y aparte están también disponible para su descarga.
Las preguntas que planteas están detalladas en el formulario de este capítulo que se puede observar en esta página o bien, está disponible para su descarga.
Gracias por tu comentario y un saludo.
MENUDO PEDAZO DE BLOG!!! DE VERDAD QUE ES DE GRAN UTILIDAD!! MUCHISIMAS GRACIAS POR EL TRABAJO QUE TE HAS TOMADO Y TE ESTARAS TOMANDO
UN ABRAZO
Buenas:
Me alegro que te sea de utilidad el contenido que aquí exponemos.
Un slaudo y gracias por tu comentario.
Hola manuel:
Quisiera que sepas que a los estudiantes que dan Estadística en la Ugr les estas haciendo un favor incalculable. Yo como uno de ellos quiero darte la gracias.
Buenas:
Me alegro que estudiantes y miembros de la Universidad de Granada les sea de ayuda el contenido que aquí exponemos.
Gracias por tu comentario.
Excelente pagina Sr.Manuel, usted cree que le es posible por favor ayudarme a resolver un ejercicio, estoy echo un lio tratando de resolverlo. Se selecciono una muestra aleatoria de 26 granos de arroz de un arrozal de un pueblo de Guadalajara. La desviacion estandar de la muestra de picados por aves por grano fue de 3. Determinar un intervalo de confianza del 95% para la varianza de la poblacion de las picaduras de ave a los granos de arroz de Guadalajara al suponer que estas mediciones siguen una distribucion normal.
Gracias por su ayuda
Buenas Tardes:
Me encanta este blog, explican los temas en forma mas clara que algunos maestros, me gustaria me ayudaran con un ejercicio o me indicaran algun ejemplo similar, La asistencia promedio a una película de estreno en 59 salas de proyección es de 82 personas. Encuentre el intervalo de confianza al 95% para la asistencia media de espectadores a esta película. Suponga que la desviación estándar de la población es 21.
Agradecere eternamente su ayuda.
atte
Ana Lucia
Buenas:
Para el ejercicio que planteas sobre la obtención del intervalo de confianza sobre la varianza, tienes cantidad de problemas resueltos, por ejemplo: Problema 12.
----------------------------
Buenas Lucía:
El ejercicio que propones es relativamente fácil, tienes uno similar en los problemas resueltos, concretamente: Problema 73.
Un saludo y gracias por tu comentario.
Buenas tardes,
te agradezco por la informacion ,es de mucha utilidad.
puedes ayudarme con este ejemplo?
En una central de mezclas de concreto se desea comparar dos procesos de fraguado en relación con la variabilidad de la resistencia a la compresión del concreto. Para este estudio se toma una muestra al azar de 7 cilindros producidos con el método de fraguado A y una muestra al azar de 10 cilindros
producidos con el método de fraguado B. Para tomar una decisión al respecto se adopta la siguiente regla: si el cociente entre las dos varianzas muestrales insesgadas es mayor a un valor crítico F se determina que uno de los procesos de fraguado produce mayor variabilidad en la resistencia a la compresión que el otro proceso. Calcular el valor de F de tal manera que se tenga una probabilidad de 0.05 de tomar una decisión incorrecta.
Buenas,
estoy resolviendo un problema sobre intervalos de confianza y me he quedado un poco atascada con uno de los apartados. El problema me dice:
Un proceso distribuido normalmente, tiene las especificaciones LIT= 75 (limite inferior de tolerancia) y LST = 85. Una muestra aleatoria de tamano 25 indica que el proceso está centrado. La cuasidesvidesviación típica de esa muestra es Sc = 1,5.
Halle una estimación puntual del CCP (o Cp, coeficiente de capacidad)
Halle un intervalo de confianza del 95% para CCP
El apartado a) se resolverlo y para el apartado b) tengo la formula pero no se como se calcula (o donde debo mirar) el valor de X_(1- ∝ /2,n-1)^2 y X_( ∝ /2,n-1)^2 . No se si son unas tablas o unas fórmulas.
He mirado tods los ejercicios que teneis sobre este tema pero no encuentro ninguno donde me den los mismos datos.
Gracias.
Perdona, no me salen bien las fórmulas. La X esta elevada al cuadrado y lo que aparece entre paréntesis es un subíndice.
Gracias
Hola! soy quien escribio los dos comentarios anteriores. Podeis ayudarme???
Gracias
Buenas A. Bella:
Para obtener los valores de las fórmulas que expones, te dejo, como ejemplo (podrás encontrar más en los problemas) el siguiente ejercicio:
· Problema 80.
Concretamente, el Apartado b), donde verás cómo se obtienen los valores con las expresiones que mencionas y acudiendo a la tabla ji-cuadrada.
· PD: Lamento el retraso, pero estoy de vacaciones y me es difícil conectarme.
Un saludo.
Sin problema! muchisimas gracias! me estas ayudando muchisimo.
Un saludo
Hola, lo siento por haber colocado una duda en otro apartado pero es que voy bastante perdida, la verdad es que sin un profesor cuesta bastante, he seguido tu consejo y me he fijado en el ejercicio 4 , me gustaria que me dijeras si voy por buen camino.
muestra: 300
media: 4 Kg de organica
desviacion estandard: 23
me pide la probabilidad producir mas de 6 Kg de organica.
Me da de probabilidad 0,0668= 6,68%
Me gustaria que me dijeras si esta bien, ya que tengo muchas dudas. Gracias.
Buenas:
Te lo resuelvo paso a paso:
Hacemos una recopilación de los datos del problema:
· Tamaño de la muestra: n = 300.
· Media muestral: x1 = 4
· Desviación estándar: σ1 = 23
Definimos la variable aleatoria continua:
· X ≡ 'Cantidad de materia orgánica, en kilogramos'
Dicha variable aleatoria continua, sigue una distribución Normal: X ~ N(4, 23)
El problema nos pide obtener la siguiente probabilidad:
· P(X > 6) = 1 - P(X ≤ 6)
Tipificamos a la Normal (mediante el Teorema Central del Límite):
· P(X > 6) = 1 - P(X ≤ 6) = 1 - P[Z ≤ √300·(6 - 4)/23]
Simplificamos:
· P(X > 6) = 1 - P[Z ≤ √300·(6 - 4)/23] ≈ 1 - P(Z ≤ 1.51)
Operamos:
· P(X > 6) ≈ 1 - P(Z ≤ 1.51) = 1 - [0.5 + Φ(1.51)] = 0.5 - Φ(1.51)
Buscamos en la Tabla de la Normal y sustituimos valores:
· P(X > 6) ≈ 0.5 - Φ(1.51) = 0.5 - 0.4345 = 0.0655
En tu caso, has redondeado a la baja, es decir:
· P(X > 6) ≈ 1 - P(Z ≤ 1.50) = 1 - [0.5 + Φ(1.50)] = 0.5 - Φ(1.50) = 0.5 - 0.4332 = 0.0668
Por lo tanto está bien. Deberías consultar el tipo de redondeo que aplica tu profesor, así no tendrás problemas cuando te examines.
Por otro lado, mi consejo es que en este tipo de problemas, en vez de redondear, apliques interpolación lineal, ya que el resultado será mas preciso.
Un saludo.
Muy buenas, no puedo tener más que buenas palabras para el blog. Si no es mucho pedirle , ¿podría ayudarme con este ejercicio d eji cuadrado, ya que no hay ninguno que pueda tomar como referencia? es que creo saber cómo es pero no estoy segura. Se lo agradecería muchísimo, y una vez que haga el examen y me quede tranquila estoy deseando poder ayudarle con una donación. Ahí va mi ejercicio:
La variable aleatoria Xv tiene distribución ji-cuadrado con v grados de libertad. Encuentre , en cada caso, el percentil X²α,v que verifica:
a) P (X10< = X²α,10)= 0,975
(los 10 son subíndices)
b) P (X15<= X²α,15)= 0,025
( 15 también es subíndice)
c) P (26,296<= X16<= X²α,16) = 0,045
Y esta creo que también es o ji cuadrado, o t-student, no sé!! :S
De una población normal de media y desviación típica desconocidas, se toma una muestra de tamaño 10 y varianza muestral S². Calcule las siguientes probabilidades:
P(S²/ σ² <=2) ; y P(1<= S²/ σ² <=1,8)
Espero que pueda ayudarme, si no, no pasa nada. Un saludo!
Hola Buenas. He de decir que este blog es una herramienta excelente para aprobar la asignatura de Estadística, y con esto me gustaría preguntar si de este tema existen ejercicios teóricos de estimadores insesgados(parte inicial del tema).
Buenas:
Vamos a ver, dependiendo de que tipo de tablas de la ji-cuadrado tengas, la resolución del ejercicio será de una forma u otra, eso sí, el resultado será siempre el mismo.
Voy a resolverte el primer apartado (ya que los demás son similares) con nuestras tablas que puedes descargarte en este blog.
Debemos obtener el percentil que verifique la siguiente expresión:
· P(X²α,10 ≥ X10)= 0.975
La obtención de la solución es directa ya que nuestras tablas están adaptadas a este apartado.
Por lo tanto, con la tabla de la ji-cuadrado delante y con los siguientes datos:
· Área de cola (α) = 0.975
· Grados de libertad (v) = 10
Obtenemos la siguiente solución: 3.25.
Te recomiendo que revises los ejercicios propuestos en el apartado de Tablas, concretamente los correspondientes a la Normal y t-Student (el manejo de tablas siempre es el mismo independientemente de que tablas sean).
Y con respecto al siguiente ejercicio, puedes hacer un cambio de variable, sabemos que la distribución ji-cuadrado presenta la siguiente definición:
· X² = (n - 1)·S²/σ²
Despejamos:
· S²/σ² = X²/(n - 1)
Y ya puedes obtener trabajar con los ejercicios.
· @Anónimo: Decirte que la parte de estimadores insesgados, está presente en este tema (los primeros ejercicios, es cierto que no hay muchos), también puedes encontrar estimadores de máxima verosimilitud más abajo.
Un saludo y gracias por vuestros comentarios.
Hola Barquero.
Tengo una duda:
En las tablas para realizar los contrastes no se cuando debo utilizar las de 'Contraste de hipótesis sobre poblaciones normales'(la llamaré TablaA) y cuando las de 'Contraste de hipótesis sobre los parámetros de una población'(la llamaré TablaB) por ejemplo en el problema nº55 cuando vamos a hacer el contraste sobre la igualdad de las varianzas tomamos el estadístico 'F' que aparece en la TablaA y ¿porque no usar el estadístico 'Z' de la TablaB?
¿Cuales es la diferencia entre ellos y cuando debemos usar una u otra? Mil gracias y saludos
Buenas:
Las tablas, al principio suelen ser un poco liosas, hasta que, con la práctica, se obtenga destreza en emplearlas.
Vamos a realizar un pequeño resumen, las tablas las podemos catalogar de la siguiente manera:
· Poblaciones Pequeñas: Emplearemos sus contrastes cuando trabajemos con poblaciones (no muestras) que estén compuestas por menos de 30 datos.
Ej: 25 placas de circuito impreso que ha fabricado una empresa electrónica.
Solo existen esas 25 placas, por lo que las consideramos como poblaciones.
· Poblaciones Grandes: Igual que las Poblaciones Pequeñas pero esta vez, los datos que la componen son igual o mayor que 30.
Ej: 100 placas de circuito impreso que ha fabricado una empresa electrónica.
Solo existen esas 100 placas, por lo que las consideramos como poblaciones.
· Muestras: Emplearemos sus contrastes cuando trabajemos con una recopilación de datos (muestras) de poblaciones. Se suele emplear estos estudios cuando las poblaciones son muy grandes o difícil de obtener.
Ej: 45 000 000 de placas de circuito impreso que ha fabricado una empresa electrónica.
Al ser muchas placas, vamos a trabajar con una muestra, por ejemplo de 100.
Llegados a este punto, respecto a tu pregunta sobre el Problema 55, se ha realizado un estudio, previo a la solución, de varianzas para decidir si son iguales o no.
Los datos que tenemos de partida son muestras (recopilación de varios datos de ambos métodos), es por ello que se ha empleado el estudio sobre varianzas (con medias desconocidas) que está recogido en el Contraste Sobre Dos Muestras Independientes.
Un saludo.
Hola buenas, hacee poco me presente a selectividad y me plantearon el siguiente ejercicio y me gustaria saber como se resuelve.
Ejercicio. El tiempo que los españoles dedican a ver la televisión los domingos es una variable aleatoria que sigue una distribución Normal de media desconocida y desviación típica 75 minutos. Elegida una muestra aleatoria de españoles se ha obtenido, para la media de esa distribución, el intervalo de confianza (188.18,208.82), con un nivel del 99%. Calcule la media muestral y el tamaño de la muestra.
Muchas gracias
Buenas:
Es un ejercicio que se resuelve a la inversa, es decir, en vez de darnos los datos y obtener el intervalo de confianza, nos dan este último dato y debemos obtener aquellos parámetros que lo satisfagan.
Te lo voy a resolver ya que en el blog no hay ninguno parecido.
Para empezar, hacemos una recopilación de datos:
· X ~ N(μ, 75)
· Intervalo de confianza de la media: [188.18, 208.82] al 99% de confianza.
Según las tablas, el intervalo de confianza de μ con σ conocida es el siguiente:
· X ± z_(α/2)·(σ/√n)
Para una confianza del 99%, obtenemos α:
· 100(1 - α) = 99
Despejamos el parámetro que nos interesa: α = 0.01. El siguiente paso es obtener el valor de la z:
· z_(α/2) = z_(0.01/2) = z_0.005
Teniendo en cuenta las características de las tablas que dispone Aqueronte de la Normal, adecuamos dicho valor:
· 0.5 - 0.005 = 0.495
Es este caso, no está el valor exacto, por lo que realizamos una interpolación lineal, el resultado es el siguiente:
· Z = 2.575
Llegados a este punto, sustituimos valores en nuestra ecuación de intervalo:
· X ± 2.575·(75/√n)
Igualamos cada ecuación con los datos del intervalo de confianza que nos dan en el enunciado del problema:
· [Ec1]: X + 2.575·(75/√n) = 208.82
· [Ec2]: X - 2.575·(75/√n) = 188.18
Tenemos dos ecuaciones con dos incógnitas (X y n), resolvemos:
· X = 198.5
· n = (12875/688)^2 ≈ 350.201175
La muestra, debe ser un número entero, por lo que podemos aproximarla por exceso (351) o por defecto (350). En este caso, al estar más próximo a 350 los datos (si obtenemos el intervalo de confianza con los datos obtenidos) serán más parecidos al dado por el enunciado.
Un saludo.
Muchas gracias por resolverme la duda.
hola, llevo tiempo intentando solucionar un problema que creo que trata sobre estimación de parámetros ver si me pueden ayudar:
Consideramos un experimento aleatorio consistente en realizar cien tiradas con un dado corriente. Calcule la probabilidad de que la media aritmética de los resultados obtenidos esté comprendida entre 3’4 y 3’6
Buenas migx:
El problema que propones no es del capítulo Estimación, Intervalos de Confianza o Pruebas de Hipótesis (no tienes el dato de la confianza/nivel de significancia).
Tú problema es del capítulo Variables Aleatorias Continuas. Vamos a realizar una recopilación de los datos propuestos por el enunciado del problema:
· n = 100 (número de tiradas del dado).
· P = 1/6 (dado normal, puede salir cualquier número comprendido entre 1-6).
El experimento sigue una distribución Binomial de parámetros B(100, 1/6).
Pero al ser el número de tiradas muy alto y teniendo en cuenta las siguientes consideraciones:
· n·p ≥ 5 --> 100·1/6 ≈ 16.666667 OK
· n·q ≥ 5 --> 100·(1-1/6) ≈ 83.333333 OK
Se puede realizar una aproximación a la Normal: N(50/3, √(125/9)).
Ahora, simplemente debes realizar la probabilidad que te piden en el enunciado del problema.
Un saludo.
hola soy Alfonso,me puede ayudar con este problema? muchas gracias de antemano. por lo menos el planteamiento
Una empresa fabrica unas píldoras,de forma que no es efectivo si la dosis es menor a 6,4 microgr.por píldora y es venenoso si es superior a 7,3 .Se ha medido el peso exacto en 10 píldora con resultado: 7,20 7,01 7,36 6,91 7,22 7,03 7,11 7,12 7,03 7,05.
con un nivel de confianza de alfa =0.001¿daria la aprobación la la Agencia Estatal del Medicamento para comercializar el producto a partir de la muestra estudiada?
Buenas Alfonso:
El problema que propones se puede abordar de varias maneras, te las expongo a continuación:
1.- FÁCIL: Realizas un intervalo de confianza, a partir de los datos del problema, y plantear una solución a tenor del resultado obtenido.
2.- LA QUE RECOMIENDO: Antes que nada, debemos asegurarnos que la dosis no sea mortal, por lo que realizamos un estudio de contrastes de hipótesis para asegurarnos que la dosis no sea mortal. En caso de que no se cumpla, es decir, si el estudio obtenido revela que la dosis es mortal, el problema termina, ya que la Agencia Estatal del Medicamento no lo va a comercializar.
En caso contrario, si la dosis no es mortal, deberemos efectuar otro estudio de contrastes de hipótesis para saber si las píldoras son efectivas o no. En caso de que el estudio revele que no son efectivas, pues la Agencia del Medicamento no concedería la aprobación de su comercialización, en caso contrario, si las píldoras son efectivas, la Agencia del Medicamento si aprobaría su comercialización.
Espero que te sea de ayuda, en caso contrario dímelo e intento asesorarte del planteamiento en forma numérica.
Un saludo.
buenas tarde soy Alfonso de nuevo para agradecerle la explicación . he hecho un intervalo y me ha quedado fuera el 6,4 y el 7,3 luego las medidas del medicamento puede ser comercializada Gracias y un saludo
ayuda con este ejercicio por favor:
En un país A la renta per cápita es de 1.000 dólares/año, con una desviación típica de 125. En otro país B, es de 1.000 dólares/año pero la desviación típica es de 560. Sólo con estos datos y tomando como criterio que el aumento de la clase media es una característica de los países en vías de desarrollo, se puede afirmar que ...
Seleccione una:
a. A es un país más desarrollado que B.
b. B es un país más desarrollado que A.
c. son dos países de un nivel similar.
d. los datos del enunciado no nos informan acerca del desarrollo.
Si no me da tiempo a realizarlos todos, que me recomiendan; Del 1 al 40 por ejemplo? Aparte los de máxima verosimilitud.
Publicar un comentario